Trots att mobiler och datorer idag har avancerad hårdvara stöter vi på sega applikationer och program. Ofta beror detta på ineffektiva algoritmer. Komplexitet används därför mest för att uttrycka algoritmens tidseffektivitet i värsta fallet, som betecknas med ett stort O.
Hur man använder komplexitet i programmering
Varför bry sig om algoritmers komplexitet?
Trots att mobiler och datorer idag har avancerad hårdvara stöter vi på sega applikationer och program. Ofta beror detta på ineffektiva algoritmer. Komplexitet används därför mest för att uttrycka algoritmens tidseffektivitet i värsta fallet, som betecknas med ett stort O.
Även om din algoritm sorterar en lista med 1000 element på mindre än 1 sekund är det inte nödvändigtvis en tidseffektiv algoritm. Vad händer om listans storlek överstiger 10 miljoner element? Vad händer i värsta fallet? Hur lång tid tar det: sekunder, minuter eller dagar?
Vad är komplexitet och stora O?
Det är bara ett sätt att uppskatta hur tidseffektiv en algoritm är. Säg att du har en lista (array) som består av n namn i strängformat, och du vill hitta ett namn i denna lista genom att söka igenom alla namn med en loop (från första till sista namnet). I bästa fallet är namnet du söker det första element. I värsta fallet är det sista element. Se följande exempel:
[ “Andreas” , “Ludvig” , “Jacob” , “Pontus”, …, “Thora” ]
Att söka efter “Andreas” kommer alltid att ta 1 operation, eftersom det är det första elementet. Även om listan hade en miljon namn skulle du hitta “Andreas” i första iterationen av loopen. Så fort du hittar namnet kan du avsluta loopen och slipper gå igenom resten av listan. I bästa fallet tar det alltså konstant tid och tiden är oberoende av listans storlek. Detta betecknas med stora omega symbolen $Ω(1)$. Det här betyder då att funktionen som beskriver bästa fallet $f(n) = k$ bara är en rät linje. Att det är en rät linje betyder att den inte beror på n (listans storlek). Se följande graf:
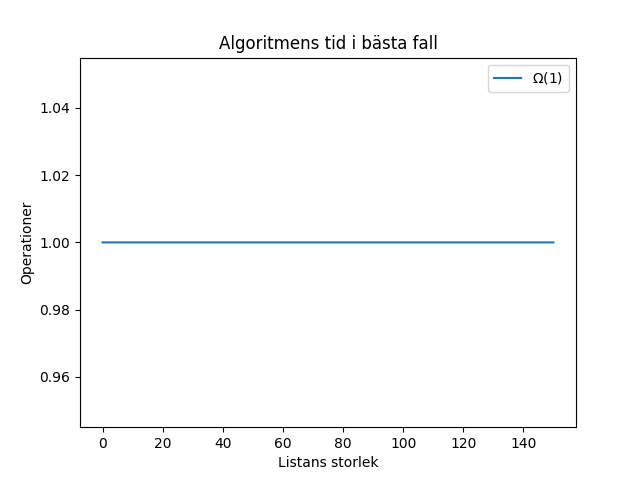
Lägg märke till att tiden inte mäts i sekunder i grafen. Operationer är ett bättre mått eftersom det utesluter datorns hårdvara. Hade vi använt sekunder hade tiden varierat från maskin till maskin trots att algoritmen är densamma. Förenklat kan man säga att 1 operation motsvarar 1 rad av kod och har komplexitet $O(1)$. (Undantaget är funktioner som kan ha högre komplexitet).
Värsta fallet är att du söker på “Thora” som ligger längst bak i listan. Då behöver du söka igenom alla namn innan du hittar namnet du sökte. Hade det varit en miljon namn hade du därför behövt söka igenom alla dessa miljoner namn. Värsta fallet betecknas med stora O symbolen, också kallad ordo. $O(n)$ betyder att tiden beror på listans storlek n och funktionen som beskriver värstafallstiden är linjär, dvs. $f(n) = n$. Med andra ord, om listans storlek var 1000 hade du i värsta fall behövt söka igenom 1000 element (vilket tar 1000 operationer). Se följande graf:
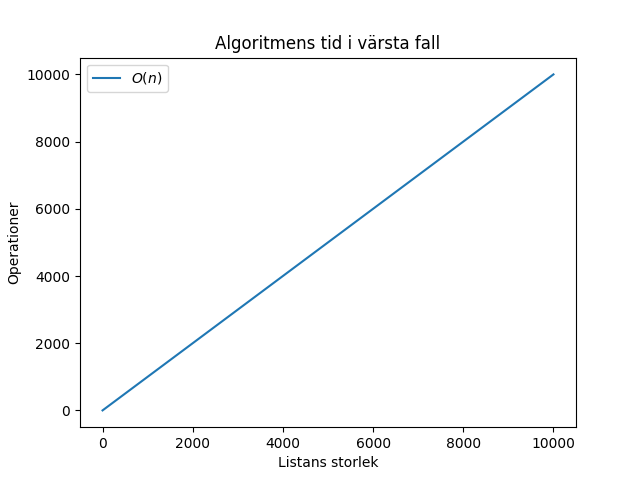
Att tänka på
När vi säger att en algoritm har komplexitet $O(n^2)$ betyder det inte att tiden kan beräknas från funktionen $f(n) = n^2$. Det betyder att denna funktion är en uppskattning av hur algoritmen växer och ser ut i värsta fallet.
Varför uppskattar vi istället för att ta reda på det exakta antalet operationer? Dels för att det är lättare att ta fram vad stora O är, men också för att det hela ändå i slutändan bara är en uppskattning. Maskiner har som sagt olika hårdvara och presterar annorlunda. Varje rad av kod utförs inte heller lika fort som andra rader.
För varje algoritm finns det en funktion $r(n)$ som ger dig det verkliga antalet operationer givet en datastorlek n. Det man kan säga är att denna okända funktion $r(n)$ har en “övre gräns” för hur den växer, som då beskrivs av stora O funktionen. Med andra ord, så länge vi vet vad stora O är för en given algoritm, vet vi hur den växer och beter sig i värsta fallet. Då behöver vi inte veta vad $r(n)$ är. Se följande exempel där $r(n)$ beskriver algoritmens verkliga antal operationer för listas storlek n. I detta fall är komplexiteten $O(n^2)$. Som du ser är de inte exakt likadana. Men ändå avslöjar stora O funktionen hur algoritmen växer.
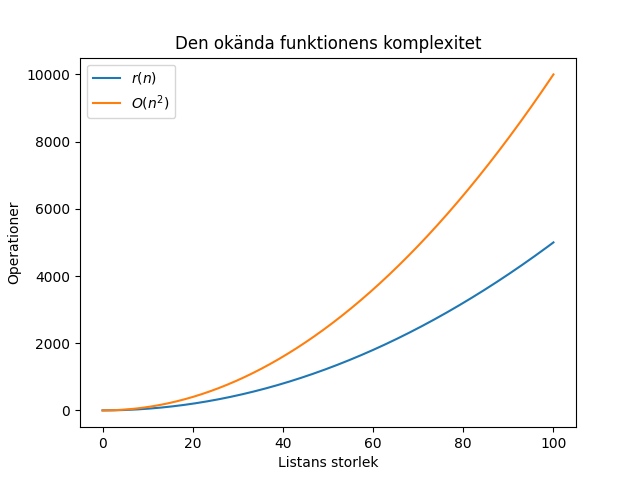
Vad är “bra” och “dålig” komplexitet?
När komplexiteten för en algoritm är känd går det att veta ungefär hur tidseffektiv algoritmen är för ett givet antal element n. För små värden på n kan det vara acceptabelt att ha en “sämre” komplexitet. För stora värden på n gäller följande:
Bra - tidseffektiv: $O(1)$, $O(log_2n)$
Okej - någorlunda tidseffektiv: $O(n)$, $O(nlog_2n)$
Dålig - för stora värden på n ökar tiden rejält: $O(n^k)$ där $k \geq 2$, $O(k^n)$ där $k \geq 2$
Väldigt dålig - även för små värden på n börjar det ta lång tid: $O(n!)$
I övrigt kan man säga att en algoritm som har konstant eller logaritmisk komplexitet $O(log_2n)$ är otroligt tidseffektiv. Titta på grafen för funktionen $f(n) = log_2n$. Den planar av mot ett värde som visar att även för många element går det mer eller mindre lika snabbt.
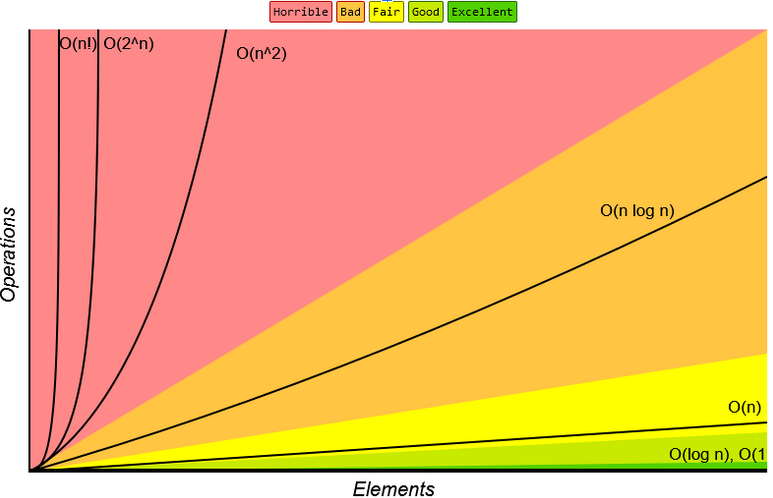
Bild tagen från https://www.bigocheatsheet.com/
Komplexiteter som är bra att kunna utantill
När man går igenom en lista och i värsta fallet behöver gå igenom alla element bör man direkt veta att komplexiteten i värsta fall är åtminstone $O(n)$.
Dictionaries (också kallade hash-tabeller eller maps) är en extremt effektiv datastruktur som ofta används när man vill lagra stora mängder unika element, som man snabbt vill kunna åtkomma. Oavsätt om det är 100 tusen eller 100 miljoner element är komplexiteten $O(1)$ för att lägga in ett element, ta bort ett element, eller slå upp ett element. Det här betyder förstås att det inte kommer bli segare och segare att slå upp något med ökat antal n, som det annars skulle göra för en lista. Starkt rekommenderat att lära sig använda denna datastruktur eftersom arrays (listor) sällan duger för större antal element.
Binära träd är också en effektiv datastruktur som har logaritmisk komplexitet $O(log_2n)$ att söka efter ett element. Detta förutsätter att trädet är "balanserat". Det är bortom denna artikel att förklara binära träd. Kortfattat kan man säga att ett binärt träd är som en lista (array) men den har strukturen av ett träd. Elementen ordnas i trädet och i värsta fallet är elementet du söker i "löven", dvs. längst ut i trädet.
Se tabellerna i denna länk för att få en översikt på komplexiteten för vanliga datastrukturer och algoritmer.
Hur räknar man ut algoritmens komplexitet?
Det vanliga sättet
Titta på koden och undersök vad förhållandet är mellan element n och operationer. I de flesta fallen kan man betrakta 1 rad kod som 1 operation. Växer antalet operationer linjärt, logaritmiskt eller kanske kvadratiskt i förhållande till n? I de flesta fallen är det loops som gör att en algoritm får en högre komplexitet.
Simulering som alternativ metod
Denna metod kan också användas för att bekräfta ditt antagande om algoritmens komplexitet. Man skapar ett program som räknar antalet operationer för ett givet värde n. Så istället för att uppskatta hur antalet operationer växer med n kan vi istället bara beräkna det exakta värdet. Fördelen med denna metod är att den är noggrannare givet tillräckligt många observationer. Nackdelen är att den tar längre tid än metoden som beskrevs ovan.
- Gör följande:
- -Skapa en variable som heter operations utanför algoritmen.
- -I den innersta loopen av algoritmen ökar du operations med 1. (Kan vara mer än 1 inre loop, då ökar du operations i båda).
- -Kör programmet för n element och anteckna operations.
- -Upprepa testet för fler n tills att du fått en uppfattning om hur operationer ökar med n.
Ett exempel är att välja n värden som 10000, 20000, 30000, 40000. Om du märker att operationer ökar konstant är det troligtvis linjär tid. Växer den mindre än linjär tid, speciellt för stora värden, är det troligtvis logaritmiskt. Växer det snabbare än linjär tid kan du undersöka om den bättre passar grafen $n^k$, $k^n$ eller $nlog_2n$. Ibland krävs fler mätvärden för att få en tydlig bild.
Exempel 1
# Funktion som tar in ett heltal n och returnerar sant om det är udda, annars falskt.
# Skriven i python.
def isOdd( n ):
if n % 2 == 0: # 1 Operation
return False # 1 Op
else:
return True # 1 Op
isOdd(2) # 1 Op
Oavsett storleken på n kommer det alltid köras 2-3 operationer (rader av kod). Detta betyder att värsta fallet för algoritmen i funktionen är $O(1)$, dvs. att tiden det tar att köra koden är oberoende av storleken på n. Observera att man inte skriver $O(3)$, är det ett konstant värde som inte beror av n räcker det att skriva $O(1)$.
Exempel 2
// Detta program söker igenom en lista med positiva heltal och skriver ut det största värdet.
// Skriven i Java
ArrayList listOfIntegers = new ArrayList(); // 1 Operation
listOfIntegers.add(1); // 1 Op
listOfIntegers.add(3); // 1 Op
listOfIntegers.add(1999); // 1 Op
listOfIntegers.add(192); // 1 Op
// För att garantera att det första heltalet blir det nya maximum i if-satsen.
int max = -1; // 1 Op
int n = listOfIntegers.size(); // 1 Op
for(int i = 0; i < n; i++) // Loopen genomför n iterationer
{
if (max < listOfIntegers.get(i)) // 1 Op
{
max = listOfIntegers.get(i); // 1 Op
}
}
System.out.println(max); // Skriver ut 1999 // 1 Op
Observera att i denna algoritm är bästa fallet = värsta fallet. Vi måste gå igenom alla element för att ta reda på det största positiva heltalet. 8 operationer utförs utanför loopen och 2 operationer utförs inuti loopen. Loopen kör totalt n gånger. Det totala antalet operationer är alltså $8 + 2n$. Som sagt är detta bara en uppskattning, komplexiteten är alltså inte $O(8 + 2n)$. Även fast det är ett noggrannare uttryck räcker det med att man skriver $O(n)$. Man tar alltså den “mest signifikanta termen” utan konstanter. Detta eftersom att funktionens tillväxt beror mest på n, speciellt när n ökar mot miljoner. Då är de där 8 operationerna försumbara och konstanten 2 som multipliceras med n leder bara till en brantare linje som fortfarande är linjär.
Exempel 3
// Detta program skriver ut en massa heltal från 0 till n
// Programmet är skrivet i C#
int n = 100;
int operations = 0;
for(int i = 0; i <= n; i++)
{
for(int j = n/2; j <= n; j++)
{
Console.WriteLine("i = " + i); // Print out i and j for each loop iteration.
Console.WriteLine("j = " + j);
operations += 1; // Just a variable that keeps track of total operations.
}
}
Console.WriteLine(operations); // Skriver ut 5000, förhållandet är alltså att för n = 100 blir i = 5000.
Hur tar man reda på komplexiteten i detta fall? Den yttre loopen kör n operationer(från 0 till n). Den inre loopen kör $n/2$ operationer(från $n/2$ till $n$). Hur många operationer blir det totalt? Om du är osäker kan du skapa en variabel som heter operationer, och sedan i den innersta loopen öka operationer med 1. Då får du en bild av hur operationer ökar med elementen n. (Denna metod förklarades tidigare).
Ett knep är att ta den inre loopens maximala antal iterationer gånger den yttre loopens maximala antal iterationer, i detta fall blir det $n \cdot n / 2$ = $n^2/2$ operationer. Komplexiteten är alltså $O(n^2)$. Som sagt skriver vi inte $O( n^2 /2)$ eftersom vi försummar alla konstanter i den mest signifikanta termen.
Exempel 4
// Ett program som utför en del av algoritm som bekräftar Lagrange's sats.
// Man behöver inte förstå algoritmen för att kunna avgöra komplexiteten.
// Skriven i C++
int operations = 0; // 1 Op
int n = 100; // 1 Op
for(int i = 0; i < sqrt(n); i++) // Loopen genomför sqrt(n) iterationer
{
for(int j = 0; j < sqrt(n); j++) // Loopen genomför sqrt(n) iterationer
{
if( i*i + j*j < n) // 1 Op
{
printf("%d and %d are sum of two squares\n", i, j); // 1 Op
}
operations++; // 1 Op
}
}
printf("%d Total operations", operations); // 1 Op
Observera igen att bästa fallet = värsta fallet. Både looparna kommer att köra alla sina iterationer eftersom det saknas break-sats. Igen tar vi den inre loopens maximala antal iterationer gånger den ytre loopens maximala antal iterationer. Vi får då $\sqrt{n} \cdot \sqrt{n} \cdot 3$ operationer totalt från loopen. Detta ger oss komplexitet $O(n)$ eftersom $\sqrt{n} \cdot \sqrt{n} = n$. Operationerna utanför loopen är försumbara.
Exempel 5
# Program som skriver ut heltal
# Skriven i python
n = 1000000 # 1 Op
# Loop A
for i in range(n): # Loopen genomför n iterationer
for j in range(n): # Loopen genomför n iterationer
sum = i + j # 1 Op
print(sum) # 1 Op
# Loop B
for i in range(n): # Loopen genomför n iterationer
print(i) # 1 Op
Här igen kan vi använda knepet att ta inre loopen gånger yttre loopen. I loop A kör den yttre loopen n gånger, och den inre loopen n gånger. I den innersta loopen utförs två operationer. Loop A kör alltså $n \cdot n \cdot 2 = 2n^2$ operationer. I loop B är det bara 1 loop som kör n operationer.
Totalt blir det $2n^2 + n$ operationer. Komplexiteten här blir inte $O(2n^2 + n)$ utan igen tar man den mest signifikanta termen och tar bort konstanterna, alltså $O(n^2)$. Detta beror som sagt på att + n termen är försumbar jämfört med $n^2$ termen för stora n.
Var försiktig med inbyggda funktioner
I majoriteten av fallen kan man betrakta 1 rad av kod som 1 operation. Ibland är detta inte fallet. Att exempelvis lägga till ett element i en lista med append tar konstant tid oavsett hur stor listan är och har alltså komplexitet $O(1)$ (append är också kallad push_back i c++). Att lägga till ett element med listfunktionen insert brukar däremot vara en dyrare operation. I python har insert komplexitet $O(n)$.
När man beräknar komplexiteten för en algoritm bör man alltså vara medveten om att 1 rad av kod inte alltid är 1 operation. Inbyggda funktioner brukar ofta ha högre komplexitet än $O(1)$.
Exempel av komplexitet i verkliga livet
Linjär tid
Låt oss säga att du tappat din penna i klassrummet och en person har den. Du har nu bestämt att du ska fråga varje person om de har pennan tills att du hittar rätt person. Det värsta fallet är att den sista personen du frågar har pennan. I värsta fallet beror alltså tiden på antalet elever n. Tiden växer förstås linjärt med ökat antal elever och komplexiteten är därför $O(n)$.
Kvadratisk tid
Thora är en lärare och vill leka en lek med sina elever för att demonstrera algoritmer som har kvadratisk komplexitet i värsta fall, dvs. $O(n^2)$. Leken går ut på att rita en graf på tavlan som visar vilka elever som känner igen varandra. Om Andreas exempelvis bara känner igen Ludde och Pontus hade läraren Thora ritat följande:
Andreas -> Ludde, Pontus
I “bästa” fallet känner ingen elev igen någon annan elev (förutom sig själv). Då hade Thora bara behövt skriva varje elev en gång som följande:
Pontus
Andreas
Ludde
Rafid
Skiller
Jenny
I “värsta” fallet känner alla elever igen varandra. Då måste Thora göra en koppling från varje elev till alla andra elever. Se följande:
Pontus -> Andreas, Ludde, Rafid, Skiller, Jenny
Andreas -> Pontus, Ludde, Rafid, Skiller, Jenny
Ludde -> Pontus, Andreas, Rafid, Skiller, Jenny
Rafid -> Pontus, Andreas, Ludde, Skiller, Jenny
Skiller -> Andreas, Pontus, Ludde, Rafid, Jenny
Jenny -> Andreas, Pontus, Ludde, Rafid, Skiller
Det blev genast många fler namn att skriva. Detta är ett exempel på en algoritm som i värsta fallet har kvadratisk komplexitet, eftersom antalet operationer ökar kvadratiskt med ökat antal elever n. I detta fall hade vi 6 elever och behöver skriva namnen $n \cdot n = 6 \cdot 6 = 36$ gånger.
Logaritmisk tid
Jacob påstår att han kan gissa vilket tal du tänker på mellan 1 - 2 000 000 på mindre än 21 gissningar, så länge han får veta om talet är mindre än eller större än hans sista gissning. Jacobs taktik är förstås att alltid gissa på värdet som är hälften av de möjliga numrena. Säg att du tänker på numret 100 000. Jacob gör följande:
Gissning 1: Tänker du på 1 000 000?
När du säger att ditt nummer är under 1 000 000 vet han att man kan utesluta alla värden över 1 000 000.
Gissning 2: Tänker du på 500 000?
Gissning 3: Tänker du på 250 000?
Gissning 4: Tänker du på 125 000?
Gissning 5: Tänker du på 62500?
Gissning 6: Tänker du på 93750?
Gissning 7: Tänker du på 109375?
Osv. tills att han hittar numret du tänker på.
Observera att i varje steg halveras antalet nummer du möjligtvis kan tänka på. Jacobs påstående stämmer, i värsta fallet kommer han hitta numret du tänker på med $log_2(2 000 000) \approx 21$ gissningar. Komplexiteten är därför $O(log_2n)$ där n är antalet värden du får tänka på.
Logaritmisk tid vs. linjär tid
Hur jämför logaritmisk tid med linjär tid $O(n)$ i detta fall? En linjär sökning hade varit att Jacob frågar dig, ett nummer i taget, från 1 till 2 000 000 tills att han gissar rätt. Och i värsta fall skulle det kräva 2 000 000 gissningar.
Om ritar graferna $f(n) = log_2n$ och $f(n) = n$ ser man att för små värden är $log_2(n)$ ger något fler iterationer först. Men så fort n ökar mot oändligheten är $log_2(n)$ överlägset bättre.